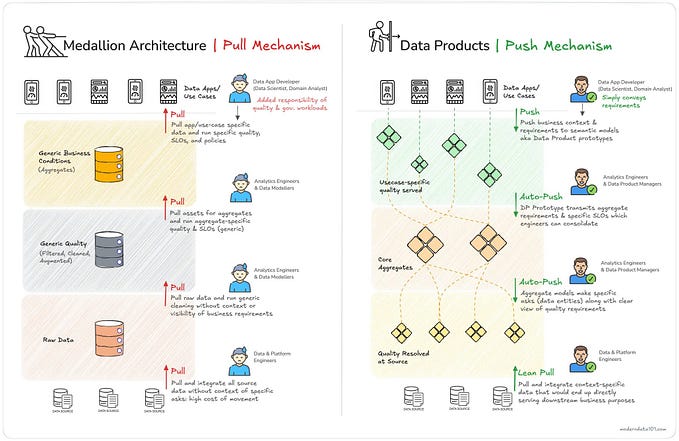
Universal data lakehouse: The most vendor/tool neutral data architecture

What is a Universal Data Lakehouse?
A universal data lakehouse is a new type of data platform that allows organizations to store and process all of their data in a single place, regardless of the data’s source, format, or use case. As defined by OneHouse, a universal data lakehouse is built on open data formats with universal data interoperability, and it provides a true separation of storage and compute. This means that organizations can ingest and transform data from any source, manage it centrally in a data lakehouse, and query or access it with the engine of their choice.
Data Lake vs. Data Lakehouse
Traditionally, data lakes have been used as a central repository for storing all of an organization’s data. However, data lakes typically lack the structure and governance required to effectively query and analyze the data. In contrast, data lakehouses combine the storage capabilities of a data lake with the structure and governance of a data warehouse. This allows organizations to not only store all of their data in a single place, but also to easily query and analyze it.
One of the key differentiators between a data lake and a data lakehouse is ACID capabilities. ACID stands for Atomicity, Consistency, Isolation, and Durability. These properties ensure that data transactions are completed reliably, preventing data corruption. Because data lakehouses have ACID capabilities, you can run queries on the data lake instead of just using data lakes for archive.
The Value of a Universal Data Lakehouse
There are many benefits to using a universal data lakehouse. As defined by OneHouse, some of the key benefits include:
- Improved data management: A universal data lakehouse can help organizations to improve their data management by providing a single place to store and manage all of their data.
- Simplified analytics: A universal data lakehouse makes it easier for organizations to analyze their data by providing a unified platform for querying and accessing data. They do this by supporting the Apache Hudi, Apache Iceberg and Delta Lake format for accessing the data. This allows the data lakehouse to support 99% of all the query engines, analytics frameworks and others in the marketplace.
- Reduced costs: By eliminating the need for separate data lakes and data warehouses, a universal data lakehouse can help organizations to reduce their data storage costs. Now you don’t need a format specific data silo (eg. Iceberg to support read heavy workloads, Hudi to support insert/upsert heavy workloads, Delta for AI/ML/Spark workloads).
- Increased agility: A universal data lakehouse can help organizations to be more agile by making it easier to access and analyze data. You can now pick the best query engine, analytics framework for the job and not be “locked-in”.
Who Builds Universal Data Lakehouses?
Several vendors offer universal data lakehouse solutions. Some of the most popular vendors include:
- Databricks
- Snowflake
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- Microsoft Azure
- OneHouse
These vendors offer a variety of features and capabilities, so it is important to carefully evaluate your needs before selecting a vendor.